
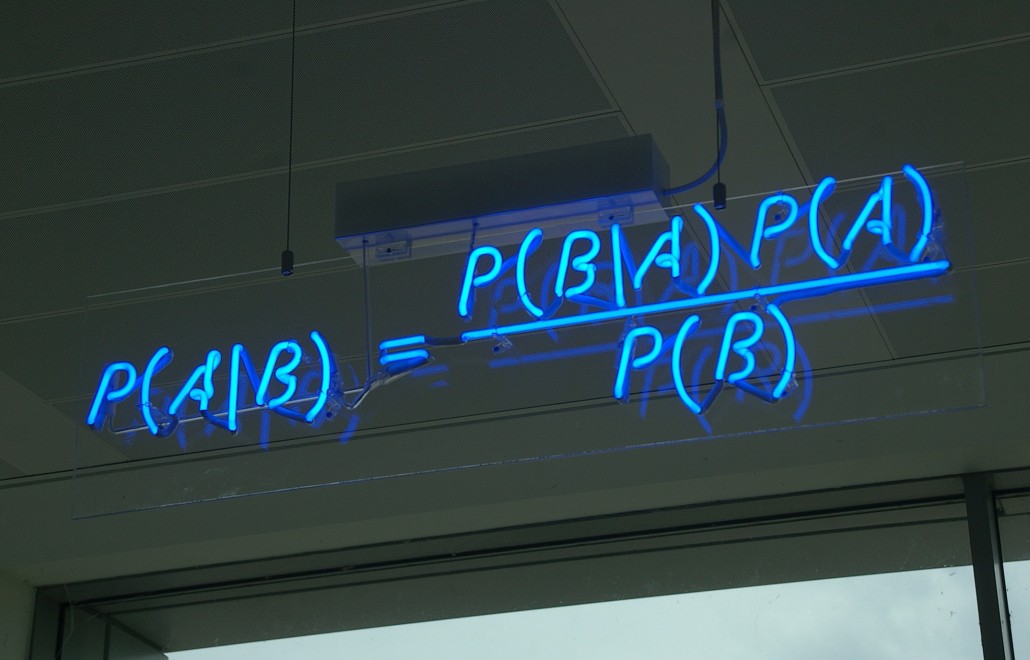
De bom van Bayes
Het ‘bewijs’ dat mensen in de toekomst kunnen kijken, zorgt voor kritiek op de statistische betrouwbaarheid van psychologisch onderzoek. Mogelijk zijn zelfs in vakbladen gepubliceerde onderzoeksresultaten niet langer te vertrouwen.
Het is bewezen. Kijken in de toekomst is mogelijk. Tenminste, dat stelt het onderzoek dat psycholoog Daryl Bem, verbonden aan de Amerikaanse Cornell University, in november 2010 publiceerde in het gerenommeerde vakblad The Journal of Personality and Social Psychology.
Op het onderzoek valt in eerste instantie weinig af te dingen. Zo deden aan de test ruim duizend mensen mee, veel meer dan gebruikelijk in de psychologie. Bovendien werd precognitie – zoals het kijken in de toekomst in bepaalde kringen heet – in 9 verschillende subonderzoeken aangetoond (zie kader Precognitie bewezen?). En al die onderzoeken doorstonden de wetenschappelijke lakmoesproef van statistische significantie. Dat betekent dat de kans dat deze resultaten zonder precognitie tot stand kwamen klein genoeg was om aan te nemen dat het mét precognitie gebeurde.
Het mag gezien het onderwerp geen verrassing zijn dat die uitkomst de nodige discussie opleverde, waarbij vooral op internet, via blogs en fora, de geschillen af en toe hoog opliepen. Ook de eerste serieuze kritiek uit wetenschappelijke kring liet niet lang op zich wachten. Eén van de vroegste criticasters was psycholoog Eric-Jan Wagenmakers, verbonden aan de Universiteit van Amsterdam. In een artikel dat hij samen met twee collega’s schreef, ging hij de onderliggende statistiek van het precognitieonderzoek te lijf. Dankzij de ontstane hype werd ook zijn onderzoek in de meningenstroom op internet al snel een hit. Het artikel werd tienduizenden malen gedownload, meer dan al het andere onderzoek van Wagenmakers bij elkaar. Het artikel is inmiddels geaccepteerd bij hetzelfde tijdschrift als waar Bem zijn precognitieresultaat publiceerde.
Bem zelf wil daarom voorlopig niet publiekelijk op de kritiek reageren. In een e-mail laat hij weten straks waarschijnlijk peer reviewer te zijn van het artikel. Hij voegt daaraan toe: ‘Vrijwel alle wetenschappelijke artikelen ondergaan tijdens het peer reviewproces nog grote veranderingen. Elk commentaar dat ik nu zou geven, is daarom vermoedelijk al achterhaald tegen de tijd van een eventuele publicatie.’
Op zoek naar een toelichting op de kritiek, treffen we Wagenmakers op zijn werkkamer in Amsterdam. In de kast staan dikke boeken over statistiek en aan de deur hangt een poster met The Bayesian Suspects; een grappende verwijzing naar de bekende misdaadfilm. Het mag dan geen verrassing meer zijn dat Wagenmakers naast psycholoog vooral ook een enthousiaste statisticus is met een voorliefde voor de bayesiaanse kansberekening. Deze vorm van statistiek werd al eeuwen geleden bedacht door Thomas Bayes (1702-1761) en later uitgewerkt door de beroemde wiskundige Pierre-Simon Laplace (1749- 1827). De methode leverde een nieuwe manier om statistiek te bedrijven. In de tegenwoordige onderzoekspraktijk blijken de uitkomsten van dit bayesiaans rekenwerk dichter aan te sluiten bij de vragen die wetenschappers in hun onderzoek stellen, zoals ‘hoe waarschijnlijk is mijn hypothese gegeven mijn resultaten?’. In dat licht lijken de antwoorden van de traditionele statistiek al snel contra-intuïtief en onhandig. Het is daarom ook niet verrassend dat bayesiaanse methoden de laatste jaren binnen het psychologisch onderzoek aan een voorzichtige opmars zijn begonnen.
Wagenmakers, die regelmatig publiceert in veelzeggende tijdschriften als The Journal of Mathematical Psychology en Psychological Methods, is een groot voorstander van die opmars. Zijn kritiek is daarom algemener dan alleen een veroordeling van de rommelige statistiek bij Bems precognitieonderzoek. Wagenmakers denkt namelijk dat het resultaat van Bem — een wetenschappelijke bevestiging van precognitieve gaven — vooral een symptoom is van een breder probleem met de traditionele statistische methoden. De titel van zijn artikel over de kwestie is wat dat betreft dan ook veelzeggend: Why Psychologists Must Change the Way They Analyze Their Data: The Case of Psi. Of, vrij vertaald: waarom psychologen anders met de verwerking van hun gegevens moeten leren omgaan.
Het grootste struikelblok is volgens Wagenmakers de veelal kritiekloze heiligverklaring van de p-waarde; de meetlat uit de traditionele statistiek waarlangs onderzoekers hun gegevens leggen. Want hoewel studenten psychologie tijdens hun opleiding uitvoerige uitleg over die p-waarde krijgen, snappen de meesten er — ook in hun latere carrière — maar weinig van. ‘In mijn colleges vraag ik vaak aan mensen om een definitie van de p-waarde te geven. Lukt dat, dan krijgen ze van mij 20 euro’, vertelt hij. ‘Bij die colleges zitten studenten met 2 jaar training in dit soort statistische methoden en toch hou ik die 20 euro altijd in mijn zak.’ En wat geldt voor studenten, geldt ook voor onderzoekers, meent hij. ‘Daar zijn enquêtes naar gedaan.’
Wie snel wil verdienen in de colleges van Wagenmakers, moet overigens de volgende definitie geven: ‘de p-waarde is de kans op een toetsingsgrootheid die tenminste zo extreem is als degene die je hebt geobserveerd, gegeven dat de nulhypothese waar is.’
Of, ontdaan van vakjargon: de p-waarde geeft aan hoe waarschijnlijk je resultaat is als de nulhypothese waar is. Niet heel ingewikkeld, dus. Het probleem is alleen dat de p-waarde een contra-intuïtief begrip is, dat geen antwoord geeft op de onderzoeksvragen. In het voorbeeld van Bems onderzoek zegt de hoogte van die waarde niets over de vraag die in het onderzoek centraal staat, namelijk ‘hoe waarschijnlijk is precognitie’, maar geeft antwoord op de vraag ‘hoe (on)waarschijnlijk is dit resultaat zónder precognitie’. En dat is niet hetzelfde.
Desondanks worden die vragen in de onderzoekspraktijk vaak toch gelijkgesteld. Als de p-waarde klein genoeg is — kleiner dan 0,05, zo luidt de conventie — mag er gepubliceerd worden (zie ook NWT Magazine, juni 2010, p. 19). Wetenschappers beschouwen de resultaten dan als ‘statistisch significant’ bewijs dat de nulhypothese (‘er is geen precognitie’) niet klopt en vervangen mag worden door een alternatieve hypothese (‘er is wel precognitie’). En daarin gaat, volgens Wagenmakers, iets structureel mis.
Dat iets onwaarschijnlijk is onder de nulhypothese wil namelijk nog niet zeggen dat het ineens wel waarschijnlijk is onder een alternatieve hypothese. Een goed voorbeeld komt uit Groot-Brittannië. Daar werd in 1999 advocate Sally Clarke-Lockyer veroordeeld voor de moord op haar twee zonen. Beide zonen overleden kort na hun geboorte aan de wiegendood. Clarke-Lockyer werd vooral schuldig bevonden op basis van de getuigenis van voormalig hoogleraar kindergeneeskunde Sir Roy Meadow, die stelde dat één onverklaarbare dood van een kind in een gezin een tragedie is, twee verdacht is en drie moord is, tenzij het tegendeel is bewezen. Later bleek dat de kans die Meadow gaf dat beide kinderen aan de wiegendood waren overleden (1 op 73 miljoen) niet klopte, omdat wiegendoden binnen één gezin niet onafhankelijk zijn (de kans werd daarop bijgesteld naar 1 op 8500). Maar belangrijker nog is dat een kleine kans alleen niet genoeg is voor een veroordeling. De loterij valt tenslotte ook elke keer, ondanks de kleine kans, en de winnaar wordt dan nooit veroordeeld voor valsspelen. Dat komt omdat de kans dat die winnaar de loterij won door vals te spelen in verhouding nog veel kleiner is. Net zo goed moest in het geval van Clarke-Lockyer de kans op ‘twee doden door wiegendood’ vergeleken worden met de kans dat een vrouw haar twee zonen zou vermoorden. En die bleek kleiner te zijn. In 2003 volgde mede dankzij het nieuwe statistische bewijs dan ook vrijspraak.
Bayesianen zoals Wagenmakers zijn er daarom van overtuigd dat het zoeken naar bewijs, wetenschappelijk of gerechtelijk, een relatief begrip is. Je moet altijd de ene hypothese met de andere vergelijken. Daarom pleit Wagenmakers ervoor om de p-waarde in de wetenschappelijke statistiek te vervangen door een bayesiaanse maatstaf. Als voorbeeld noemt hij de zogeheten bayesfactor, die weergeeft hoeveel waarschijnlijker de resultaten onder de ene hypothese zijn in vergelijking met de ander.
Maatstaf
In tegenstelling tot de traditioneel statistische p-waarde, maakt deze bayesfactor direct inzichtelijk hoe goed de gevonden onderzoeksresultaten zijn. Als de bayesfactor 3 is, wil dat zeggen dat de alternatieve hypothese (‘er is precognitie’) een driemaal zo waarschijnlijke verklaring voor de gevonden resultaten biedt dan de nulhypothese (‘er is geen precognitie’). En dat is precies wat een onderzoeker wil weten. In vergelijking met het instinctieve gemak van de bayesfactor, lijkt de p-waarde als maatstaf dan al snel onhandig en achterhaald.
Om te laten zien dat die bayesfactor inderdaad een meer rigide alternatief is, paste Wagenmakers hem toe op de resultaten van Bem. Die bleken daardoor als sneeuw voor de zon te verdwijnen. Van de 9 onderzoeken die precognitie bewezen, gaf er nu nog slechts één ‘substantieel’ bewijs voor de alternatieve hypothese (precognitie). Substantieel wil in dit geval zeggen dat de alternatieve hypothese als verklaring voor de gevonden resultaten tussen de 3 en 10 keer zo waarschijnlijk is als de nulhypothese (geen precognitie). Verder bleek echter ook dat drie testen nu juist ‘substantieel’ bewijs leverden voor de nulhypothese. Precies het tegenovergestelde dus van wat Bems oorspronkelijke onderzoek op basis van p-waarden concludeerde. Bij de overige testen was de bayesfactor zo laag dat er geen zinnige uitspraak te doen was welke hypothese nu precies waarschijnlijker was. Gesterkt door deze resultaten waagde Wagenmakers zich samen met collega’s aan een vervolgonderzoek dat inmiddels geaccepteerd is door het tijdschrift Perspectives on Psychological Science. Daarin bekeek hij de statistische resultaten van 252 artikelen uit de jaargang 2007 van twee vakbladen uit de experimentele en cognitieve psychologie: Psychonomic Bulletin & Review en Journal of Experimental Psychology: Learning, Memory and Cognition. Daarin waren 855 statistische berekeningen te vinden met een bepaalde p-waarde (ongeveer 3 berekeningen per artikel). Van al die resultaten berekende Wagenmakers de bayesfactor.
In tegenstelling tot bij het onderzoek van Bem, bleek in dit geval dat de bayesiaanse statistiek vaak een voorkeur had voor de alternatieve hypothese; precies wat je zou verwachten als de gevonden resultaten gewoon kloppen. Toch was er wel degelijk een belangrijk verschil. De bayesfactor gaf namelijk bijna altijd een lagere waarschijnlijkheid. Van de statistische berekeningen met een relatief hoge p-waarde – tussen de 0,05 en 0,01 – bleek 70 procent niet te voldoen aan de nieuwe eisen. Daarbij bleek de alternatieve hypothese maximaal driemaal zo waarschijnlijk als de nulhypothese. ‘Dat is bijna niets’, meent Wagenmakers. Dergelijke resultaten worden door bayesianen over het algemeen geclassificeerd als ‘anekdotisch’ of ‘nauwelijks het vermelden waard’.
Vertrouwen
Toch is niet iedereen ervan overtuigd dat de bayesiaanse statistiek de enige weg naar het licht is. ‘De resultaten van Bem waren op basis van de geringe effecten die in het artikel werden beschreven sowieso al niet erg overtuigend’, vertelt psycholoog Willem Heiser, van de masteropleiding Statistical Science for the Life and Behavioural Sciences van de Universiteit Leiden. ‘De bayesiaanse statistiek is wel in opkomst, maar het psychologisch onderzoek is een soort olietanker. Je krijgt het niet zo snel van koers’.
Heiser bevestigt desgevraagd wel dat blind varen op alleen de p-waarde onverstandig is. Maar hij benadrukt ook dat wetenschappers meestal niet alleen de p-waarde vermelden in hun artikelen, maar ook de zogeheten effect size; een statistische maat voor de grootte van het onderzochte effect. Is die klein en is de p-waarde ook niet zo overtuigend, dan is dat voldoende om de resultaten in twijfel te trekken, of ze nu gepubliceerd zijn of niet. ‘Technisch gesproken hebben Wagenmakers en collega’s met hun pleidooi voor bayesiaanse methoden gelijk, maar het is zeker niet de enige goede manier om statistiek te bedrijven’, vertelt Heiser.
In de praktijk vraagt Wagenmakers zich echter af hoeveel die effect size nu precies uithaalt. ‘Het lijkt wel wat op ritueel handenwassen. Een bezwering om te doen op je gegevens, waarna die als gezegend kunnen doorgaan’, denkt hij. ‘Reviewers van artikelen kijken er niet echt naar en in de praktijk denkt men er nog nauwelijks over na wat die gegevens nu precies betekenen.’
Wagenmakers heeft daarom steeds minder vertrouwen in de uitkomsten van in vakbladen gepubliceerd onderzoek. ‘Met de huidige toetsingsmethoden kun je bereiken wat je maar wilt, zolang je inventief genoeg te werk gaat’, meent hij. Als je je gegevens maar voldoende masseert en met mooie, onverwachte uitkomsten op de proppen komt, kun je al snel publiceren in gerenommeerde tijdschriften. ‘Nu is het tijdschrift Psychological Science bijvoorbeeld erg hip. Daarin bevestigt men de laatste tijd de ene na de andere contra-intuïtieve hypothese.’ Een goed voorbeeld is het recente onderzoek dat bewees dat vrouwen hun vaders minder vaak bellen als zij op hun vruchtbaarst zijn; volgens de onderzoekers misschien een evolutionair overblijfsel van een instinct om incest te voorkomen. Wagenmakers noemt ook het onderzoek waaruit bleek dat vrouwen minder positief staan tegenover andere rassen als ze vruchtbaar zijn. Dat zou blijken uit een ingewikkelde indirecte test, waarbij proefpersonen afwisselend plaatjes van zwarte en blanke mensen voorgeschoteld kregen en positieve en negatieve woorden. Als ze vaker met dezelfde hand op de negatieve woorden en op plaatjes van een ander ras drukten, zou dat voldoende bewijs zijn voor negatieve gevoelens. Deze tweetrapstest had een p-waarde van 0,04 en is daarmee dus publiceerbaar, maar ook direct verdacht. ‘Ik heb de statistiek niet zelf nagerekend’, geeft Wagenmakers toe, maar hij plaatst bij veel van dit soort hippe uitkomsten desondanks zijn vraagtekens.
Een concreet voorbeeld van onderzoek dat bij nader inzien op statistisch drijfzand gebaseerd bleek, is het artikel Doing is for Thinking! Stereotype activation by stereotypic movements van de Duitse psycholoog Thomas Mussweiler, verbonden aan de universiteit in Keulen. In dat onderzoek — dat in 2006 in hetzelfde Psychological Science verscheen — probeerde Mussweiler vast te stellen of bepaalde handelingen onbewust bepaalde stereotypen kunnen ‘activeren’. Hij zorgde er daarom voor dat de helft van zijn proefpersonen op dezelfde manier ging bewegen als mensen met overgewicht, terwijl de andere helft, de controlegroep, dat niet deed. Volgens Mussweiler bleek dat de mensen die anders bewogen later ook meer stereotypische dikke eigenschappen toewezen aan derden dan de controlegroep.
Het resultaat bleek uiteindelijk nét op het randje statistisch significant. De p-waarde van het onderzoek was 0,05, precies op de publicatiegrens. Het onderzoek werd echter kracht bijgezet door de effect size; die volgens de gebruikelijke statistische labels ‘groot’ tot ‘zeer groot’ was. Al met al voldoende bewijs dus om tot publicatie over te gaan.
Wie echter vervolgens de bayesfactor van dit onderzoek uitrekent, ziet dat het resultaat vermoedelijk toch op toeval berust. Een analyse van Wagenmakers en collega’s leverde een bayesfactor van 1,56. Met andere woorden: de in het onderzoek geponeerde hypothese is nauwelijks waarschijnlijker dan de nulhypothese. Onder bayesiaanse maatstaven was dit resultaat dus nooit in een vakblad verschenen.
Dat dit soort onderzoek uiteindelijk toch die vakbladen haalt, heeft overigens meer te maken met de druk op wetenschappers om te publiceren, dan met de statistiek. Wagenmakers pleit er daarom voor om onzinresultaten en statistische missers zo snel mogelijk uit te filteren. ‘Als iets eenmaal gepubliceerd is, heeft het een bepaalde status’, vertelt Wagenmakers. En wie dan nog het tegendeel wil beweren, moet sterk in de schoenen staan.
Overigens zijn dit soort statistische problemen niet alleen voorbehouden aan de psychologie. ‘Dit probleem tref je ook in veel andere sociale wetenschappen en bijvoorbeeld in de economie. Eigenlijk overal met een sterke p-waardecultuur.’
Als critici als Wagenmakers inderdaad gelijk hebben, is het dus slecht gesteld met de betrouwbaarheid van veel wetenschappelijke resultaten. Want als je zelfs gedegen onderzoeksresultaten, gepubliceerd in gerenommeerde peer reviewed tijdschriften niet meer kunt vertrouwen, wat dan nog wel? Bayes mag het weten.
Publicatiegrens
Eén van de hoofdargumenten om over te stappen van de traditionele statistiek naar bayesiaanse statistiek, is dat de huidige publicatiegrens voor de p-waarde (0,05) teveel verdachte resultaten tot ‘statistisch significant’ bombardeert. Veel van dat bezwaar zou echter direct wegvallen als wetenschappers het eens kunnen worden over een stringentere publicatiegrens op p < 0,01; de waarde vanaf waar in het onderzoek van Eric-Jan Wagenmakers alle resultaten ook onder de nieuwe bayesiaanse maatstaf overeind blijven.
Inderdaad bevestigen Wagenmakers en collega’s al in de conclusie van hun onderzoeksartikel dat zo’n nieuwe grens een hoop zal schelen. Desondanks blijven zij van mening dat een bayesiaans alternatief beter is. Zo is de bayesfactor intuïtief duidelijker en geeft het antwoord op twee vragen: of er een effect is en hoe groot dat effect is. In de traditionele statistiek worden die vragen door aparte grootheden (de p-waarde en de effect size) beantwoordt. Bovendien opent het gebruik van de bayesfactor de deur naar invoering van nog meer bayesiaanse statistiek in de onderzoekspraktijk. Door bayesiaanse rekenregels te gaan gebruiken, zou het in de toekomst bijvoorbeeld gemakkelijker moeten worden om de resultaten van verschillende onderzoeken samen te voegen tot één statistische uitspraak over de juistheid van een bepaalde hypothese.
Precognitie bewezen?
De toekomst kan mensen beïnvloeden in het heden. Dat onwaarschijnlijke resultaat volgde uit het controversiële precognitieonderzoek van psycholoog Daryl Bem. Bem liet vrijwilligers — studenten aan de universiteit waar hij zelf ook werkzaam is — bekende psychologische fenomenen testen; maar dan achterstevoren.
Normaal zijn proefpersonen bijvoorbeeld in staat sneller een afbeelding als positief of negatief te herkennen als zij eerst heel kort een positief of negatief woord (‘mooi’ of ‘lelijk’) zagen. Bem keerde dat om.
Studenten bleken in zijn onderzoek zo’n 15 milliseconden sneller in staat een negatief plaatje als negatief te herkennen als ze na afloop een negatief woord (‘bedreigend’ of ‘bitter’) te zien kregen; hetzelfde gold voor positieve plaatjes. Het was net of hun onderbewuste reageerde op het woord dat ze in de toekomst te zien zouden krijgen.
In een andere proef schotelde Bem de studenten twee digitale gordijnen voor en liet hen gokken achter welk gordijn een erotische afbeelding te vinden was. De studenten bleken in 53,1 procent van de gevallen in staat om de afbeelding te vinden; meer dus dan de 50 procent die je bij een willekeurige verdeling zou verwachten. Het verschil was genoeg om het resultaat tot statistisch significant te bestempelen. Opmerkelijk genoeg lukte het de studenten bij normale plaatjes juist niet om het juiste gordijn te kiezen (slechts 49,8 procent). In een laatste voorbeeld liet Bem de proefpersonen kijken naar een scherm met twee plaatjes waaruit ze hun favoriet moesten kiezen. Na de keus schoof het programma over één van de twee plaatjes kort een onaangename afbeelding. De proefpersonen kozen net iets vaker voor de kant waar daarna niets gebeurde. Het was dus net alsof ze aanvoelden waar de onaangename afbeelding zou gaan verschijnen.
In 9 van dit soort proeven vond Bern bewijs voor precognitieve gaven. Daarmee levert hij één van de eerste serieuze ‘bewijzen’ voor precognitie in de vakliteratuur.
Dit verhaal is eerder verschenen in NWT Magazine









Plaats een Reactie
Meepraten?Draag gerust bij!